摘要:AI大模型到底是什么?它不是”智能”,而是一个超级高级的概率机器——本质上是”词接龙”。本文用硬核的方式拆解GPT-5、Claude Opus 4.7、DeepSeek-V4等2026年最新模型的工作原理:Transformer架构、涌现现象、统计知识、推理真相,以及AI真正的强项和根本局限。看懂这篇文章,你对AI的认知会超过90%的人。
—
2025年,GPT-5发布,ChatGPT全球用户突破2亿。2026年,Claude Opus 4.7、Mythos、DeepSeek-V4轮番炸场。
但我敢打赌,90%的人不知道AI大模型到底是怎么工作的。
今天来一个真正硬核的科普。不讲”它很聪明”,讲”它到底是什么”。
【一】先泼一盆冷水:AI不懂任何东西
先纠正一个普遍误解—— AI大模型并不理解你说的话。 它不是在”思考”,它不是在”理解”,它在做一件更底层的事: 预测下一个词。 这就是大语言模型(LLM)的本质——一个超级高级的”词接龙”机器。 你输入”中国的首都是”,它计算的是:给定这些词序列,下一个词最可能是什么? 答案是”北京”。不是因为他知道北京是首都,而是因为”北京”在训练数据中紧跟在”中国的首都是”后面的概率最高。 它做的事情,和你的手机输入法联想下一个词没有本质区别。 只不过,GPT-5的参数是数万亿个,而你的手机输入法大概是几百万个。差了七到八个数量级。【二】那它凭什么看起来像在思考?
好问题。 既然本质是概率机器,为什么它能写代码、能做数学题、能帮你写邮件、能把复杂概念解释清楚? 答案是两个字:涌现(Emergence)。 涌现是复杂系统研究的核心概念——当一个系统的规模大到一定程度,会自发出现组成它的简单单元根本不具备的能力。 举个例子:- 一个水分子没有”湿”这个属性,但一大堆水分子聚在一起就有了
- 一个蚂蚁没有”智慧”,但蚁群可以修桥、种地、蓄养蚜虫
- 一个神经元不会”思考”,但860亿个神经元连在一起,就产生了意识
【三】它的”知识”从哪来?
四个字:统计模式。 GPT-5的训练数据主要是互联网文本——网页、书籍、论文、代码、论坛帖子。 它并没有一个独立的”知识库”。它的”知识”,是它从海量文本中统计出来的词语之间的关联关系。 举个例子。 当你问它”水的沸点是多少”,它回答”100°C”。 实际上它做的事是:在它的训练数据里,”水的沸点”后面跟”100°C”的概率极高。它找到了这个统计规律。 但这意味着—— 它不知道什么是水,不知道什么是沸点,不知道什么是摄氏度。 它只是在玩一个超级精密的”词语关联游戏”。 这带来一个严重问题:它会自信地胡说八道。 因为它的训练数据里既有正确答案,也有错误答案。如果错误答案出现的频率够高,它就会把错误答案当成”正确答案”来输出。 更危险的是——它的胡说八道通常语法正确、逻辑通顺、语气自信。 一个不知道自己在胡说的人,危害有限。一个不知道自己在胡说、但说话极其自信流畅的机器,危害大得多。【四】它的”思维”到底是怎么回事?
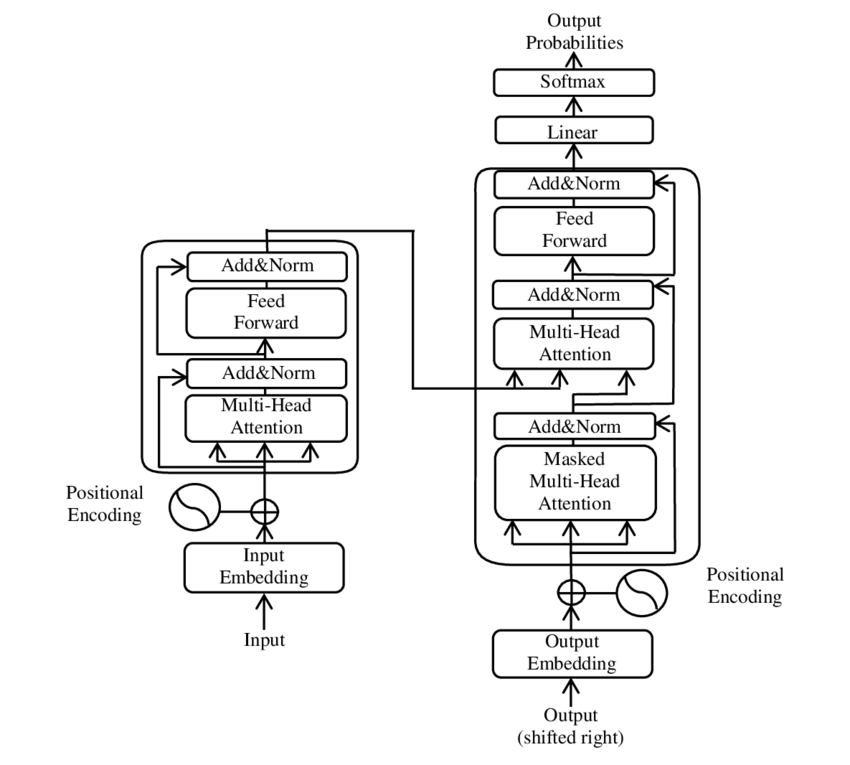
当你在和ChatGPT对话时,它在底层到底发生了什么? 它把输入的文本转换成一个数学对象——向量(准确地说,是高维张量)。然后经过层层Transformer架构的神经网络处理,最后把处理结果再转换回文字输出。 Transformer是什么? 2017年,Google在一篇叫《Attention Is All You Need》的论文里提出了这个架构。它是今天所有大语言模型的基石,包括GPT-5、Claude Opus 4.7、DeepSeek-V4全部基于Transformer。 上图就是Transformer的核心架构图—— Encoder-Decoder结构,配合自注意力机制(Self-Attention),让模型能够关注输入序列中最相关的部分。 “Attention”的意思是”注意力机制”。它的核心思想是: 当模型处理一个词的时候,它需要”看”输入序列里的其他词,来决定这个词应该是什么意思。 具体怎么做? 每个词都有一个”向量表示”(可以理解为一个数字列表)。Attention机制做的事,是计算每个词和其他所有词之间的”相关性分数”——这个词和那个词有多相关? 比如在”猫坐在垫子上”这句话里:- 处理”坐”的时候,它会注意到它和”猫”相关性高,和”垫子”相关性也高
- 处理”猫”的时候,它会注意到它和”坐”相关,和”垫子”相对不那么相关
【五】2026年的模型”推理”到底怎么回事?
最让外行人震惊的,是大模型似乎能做推理。 比如:问:我的书架有三层。我把5本书放在最上层,8本书放在中间层。最下层比最上层多3本书。问最下层有多少本书? 答:最下层有8本书。8 = 5 + 3。它做对了一道数学推理题! 但研究者发现,这件事背后的机制,和人类做数学题的机制完全不同。 它是怎么”做”的? 它其实是在模仿训练数据里大量的”数学问题+解题过程”文本。它学会的是”遇到这种格式的问题,应该输出什么样的步骤和答案”。 换句话说——它在模仿解题,不是在解题。 这带来一个很诡异的现象:
- 如果一个问题和它见过的某类问题足够像,它能做对
- 如果一个问题稍微超出它的训练分布,它就会犯人类绝对不会犯的错误
- 两位数乘法它能做对,但三位数乘法可能突然就错
- 它可以教你写代码,但代码里的bug可能比它帮你修的还多
【六】那它到底有什么用?
说了这么多”它不能做什么”,现在说它能做什么。 大语言模型真正的强项,是处理语言形式的变换。 具体来说,它擅长: 写作辅助 — 它不”懂”写作,但它见过海量的文本,所以它知道你想要什么样的风格、格式、结构。它能帮你起草、润色、修改。前提是——你得有能力判断它的输出质量。 信息整合 — 它读过的东西太多了,它知道很多事情之间的关联。它能做”我今天看了X篇论文,帮我总结异同”这种事,前提是——你得有能力判断它的总结是否准确。 代码生成 — 它看过海量的开源代码,它知道大多数常见编程任务的”标准写法”。它能帮你写模板代码、解释代码、debug代码。前提是——你得有能力判断代码是否正确。 核心规律就一条:AI放大的是你的能力,而不是填补你的无知。 一个领域专家用它,效率翻倍,甚至十倍。 一个领域新手用它,很可能得到一堆听起来很对但完全错误的东西。【七】它的局限到底是什么?
大语言模型的根本局限: 1. 没有真正的知识,只有统计相关性 它知道的”事实”可能随时出错,尤其是需要精确记忆的信息(日期、数字、专业术语)。 2. 没有真正的推理,只有模式匹配 它能模仿推理过程,但遇到超出训练分布的问题就会失败。 3. 没有真正的意图,只有概率输出 它不会主动帮你发现真正的问题,它只会响应你的输入。 4. 不知道自己有局限 它会自信地输出错误信息,而且很难自我纠正。 5. 缺乏持续学习能力 它无法像人类一样,从一个例子中立即学会新知识。它的”学习”发生在训练阶段,不是使用阶段。【八】2026年了,AI现在什么水平?
GPT-5、Claude Opus 4.7、DeepSeek-V4、Anthropic Mythos——这些模型已经代表了2026年最前沿的水平。 斯坦福AI Index 2026报告指出几个关键趋势: 多模态成为标配 — GPT-5和Claude Opus 4.7都能处理文字、图像、音频、视频,已经不是单纯的语言模型。 工具使用(Agent)爆发 — 大模型 + 搜索引擎 = 实时知识;大模型 + 代码执行器 = 精确计算;大模型 + 外部API = 真正做事。Agent赛道在2025-2026年彻底爆发。 可靠性仍在改善 — 胡说八道问题通过RLHF、CoT、RAG等技术有所改善,但根本问题没有解决。 能耗和成本成新瓶颈 — AI公司正在用”Bragawatts”(十亿瓦特)来衡量AI系统的能源需求,大模型的算力成本问题成为新焦点。 但一个根本问题不会变—— 大语言模型是语言的形式系统,它处理的是符号之间的关系,不是符号背后的真实世界。 除非有人真正解决”AI如何理解真实世界”这个难题,否则大模型的本质不会改变。结语
下次你再和ChatGPT或Claude对话的时候,记住一件事: 你不是在和一个”智能”对话。 你是在和一个见过人类有史以来最大规模文本库的超级统计机器对话。 它不是你的朋友,不是你的老师,也不是你的敌人。 它是一面镜子——你问的问题越好,它给的答案越有价值。 所以问题的关键从来不是”AI有多强”,而是”用AI的人有多强”。 这个结论,可能比AI本身更值得你记住。如果觉得有用,点个赞
转发给朋友看看
关注我,每天更新热点资讯